
AI Networking Companies Are Set For Capex Primetime
How Broadcom, Marvell, Arista Networks, Celestica, & other networking companies benefit from AI Capex budgets.



Lets Set The Stage…
Three months ago, when Broadcom’s AVGO 0.00%↑ Hock Tan announced his company’s Q4 report and closed out their FY24, he revealed eye-popping numbers about an additional ~$75B SAM, or Serviceable Addressable Market, that the company could benefit from. This sent a rush of blood to the heads of all market bulls, with Broadcom rising ~40% over the next two days.
Of course, Broadcom, like most other tech stocks, has gotten hit hard by the tariff trauma along with the heightened semiconductor shipments scrutiny doing the rounds on Wall St. these days. Still, after soaking in the recent AI Capex outlook from all the hyperscalers, one can see pathways towards Hock Tan’s lofty ~$75B SAM targets.
However, tucked away in Tan’s ebullient SAM outlook were some interesting details about a lesser-known segment of the AI data center that isn’t as flashy as Nvidia’s GPUs—AI Networks & Connectivity Solutions.
The AI Connectivity market is not a sector that usually grabs as much attention, but it still is an important part of every cloud company’s plans for upgrading existing or laying out new data center infrastructure. The networking products by AI Connectivity companies can also get technically complex for investors to understand, which keeps some investors at bay.
So we decided to do a deep dive into the AI Connectivity market, which should help anyone understand the intricacies of AI Networks & Connectivity.
We have broken this out as a multi-part series, with today’s free post intended to be a primer on delving into the basics of AI Connectivity companies, the different technologies, and how they intertwine with Nvidia’s GPUs or Broadcom’s XPUs and the like.
We will be following up this free post with specific stock analyses about companies in the AI Networking space for paid members. Our analyses will cover the growth outlooks and price targets of specific AI networking companies.
We’re currently running a limited time offer for all new subscribers to lock in $80 annually for a lifetime. Prices will go up to $160/year on March 17.
Sign up as a premium member by clicking on the link below.👇
The 101 On Connectivity Solutions In AI Data Centers
(🥱TLDR alert: If you consider yourself to be a Network Ninja or just dont care about nerding out on networking, scroll down to the next section.)
To be clear, there is nothing really like an AI Data Center. It’s just that most hyperscalers and large technology enterprises started building out data centers (or upgrading them) around 2022 to specifically process AI workloads such as training, post-training, computer vision, etc.
Most of these data centers, which are solely architected to process AI workloads, rely on GPUs to do most of the heavy lifting. Since Nvidia dominates the GPU-in-the-Data Center market, it makes sense to start this 101 section on AI Connectivity by perusing through Nvidia’s networking reference designs for the AI data center.
(🤓Don’t worry, we’ll try to simplify this as much as possible.)
On the outside, what most novices like us get to see is a data center full of servers that looks like the Nvidia DGX SuperPOD below.👇

Nvidia defines a pod, also called a cluster, as a set of GPUs linked by high-speed networks or interconnects into a single unit. A SuperPOD is a collection of pods also interconnected by high-speed networks to form a larger single unit like the one above.
Most data centers employ the same type of network architectures, more or less, whether they use Nvidia’s HGX H100, AMD’s MI300X, Intel’s Gaudi, AWS Trainium, etc.
Popular semiconductor research blog SemiAnalysis believes even Nvidia’s latest Blackwell-based GB200 systems use the same network architecture. According to the blog, there are 4 main types of networks usually employed in the data center:
Frontend Networking (Normal Ethernet)
Backend Networking (InfiniBand/RoCE Ethernet)
Accelerator Interconnect (Nvidia’s proprietary NVLink, open-sourced UALink)
Out of Band Networking (Normal Ethernet)
Generally, Out of Band networks are separate, dedicated fabrics of networks used mostly by the data center’s network administrators to manage all devices on the network. This can be seen as low throughput, a networking metric measuring the volume of data passing through at any period, and is generally not the high-margin dollar-generating revenue stream for networking companies.
Frontend Networks act as the initial checkpoint for all data coming into the data center, which will eventually be used for training models and other AI workloads. It’s basically just a normal Ethernet-based network the data center uses to connect to the global internet, scrape data off the internet, load it in the data center, pre-process and process the data, etc. Frontend networks are typically 25-50 Gb/s per GPU, so on an Nvidia HGX H100 server, it will be 200-400 Gb/s per server, while on Nvidia’s GB200 computer tray node, it will be 200-800 Gb/s per server depending on the configuration.
Backend Networks are used to scale out GPU-GPU communications across hundreds to thousands of server racks. These networks are typically high in network throughput since they are primarily used to train AI models. Due to the critical nature of AI workloads that the backend network handles, it is extremely crucial that this network operate at superior levels of network efficiency, low latency, high bandwidth, etc. So hyperscalers and other data center companies are usually loose with their purse strings when spending their capex dollars on the backend networks.
Nvidia’s InfiniBand was one of the preferred products that were initially used, but InfiniBand can rack up huge fees due to reasons we’ll explain later, so hyperscalers quickly pivoted to using products from custom semiconductor companies such as Broadcom and pure-play networking vendors such as Arista Networks ANET 0.00%↑, Cisco CSCO 0.00%↑ etc.
Finally, Accelerator Interconnects are used to scale up GPUs on the same server system. These intra-networks as well are extremely crucial for AI workloads and capture a majority share of AI capex dollar budgets as well. For example, on Nvidia’s Hopper, this network connected 8 GPUs together at 450GB/s each, while on Blackwell NVL72, it connected 72 GPUs together at 900GB/s each. But in general, the accelerator interconnect is 8-10x faster than the backend networking.
Scalability is an extremely sensitive issue most data center architects solve for when designing data centers since AI workloads are expanding at breakneck speed. As AI applications grow in complexity and AI workload, the underlying infrastructure must ensure that network performance can keep pace with increases in computational power and data volume.
This post on Microsoft Azure’s official blog page explains the difference between scale up and scale out. Simply put, scaling up is adding further resources, like GPUs or XPUs, hard drives, memory, etc., to increase the computing capacity of a server. On the other hand, scaling out is adding more servers to your architecture to spread the workload across more machines so if any particular server hits its capacity limits, the AI workloads can be processed on other server systems in the data center.
(🛑If you haven’t noticed already, go back up and review keywords such as scale up and scale out. Most networking executives contextualize the dollar size of their target markets based on their outlooks for scale up and scale out networks.)
At this point, if you are still trying to wrap your head around all the different networks, let us simplify this for you with a diagram that shows how data center architecture evolved over the past few years to accommodate the growing volume of AI workloads.

Focus on the evolution of complexity in the architecture, which introduced several more nodes in the architecture. For networking companies, the significant spike in the number of nodes in the network is music to the ears—more network nodes means more points to connect, which means more product to sell.
If you need to zoom out and get a higher bird’s-eye view, here is an easier network topology architecture chart from the engineering team at Meta Platforms META 0.00%↑ that abstracts some of the complexities to summarize what we discussed in this section.

Meta’s engineering team succinctly summarizes everything that we just discussed for one of their server cluster networks as:
The training [server] cluster relies on two independent networks: the frontend (FE) network for tasks such as data ingestion, checkpointing, and logging, and the backend (BE) network for training.
The reality is that data center architects work with network engineers to design the data center, like the DGX SuperPOD Server system we saw in Exhibit A above, with these four network architectures.
Network engineers deploy a host of networking products such as switches, routers, retimers, memory controllers, wires, cables, NICs, or Network Interface Cards, etc., when laying out the network in data centers and connect all the myriad of endpoints in the data center.
Most of these networking products are manufactured by companies we will briefly touch upon through the post, and all products are manufactured in accordance with particular networking industry standards. For example, switches, routers, and cables can either be developed on Ethernet or PCIe standards. For accelerator interconnect solutions, Nvidia created their own proprietary NVLink standard, whereas Nvidia’s peers joined hands and created the open-source UALink standard for scale up networks.
⏰⏰Less than 2 weeks left to unlock your lifetime annual subscription price of $80 and unlock long-term investment opportunities in the AI landscape with stronger-than average growth trajectories and high probability of success as we navigate the fast evolving innovation landscape
The Case For AI Connectivity Companies & Revenue Reacceleration
With the 101 on AI Networking out of the way, it’s a good time to circle back to the comments from the Semiconductor Soothsayer, Broadcom’s Hock Tan, about his multi-year SAM targets:
In December 2024, Tan spoke about the additional SAM that he was seeing after noting the data center infrastructure plans of each of his three hyperscaler customers:
In 2027, we believe each of them plans to deploy 1 million XPU clusters across a single fabric. We expect this to represent an AI revenue Serviceable Addressable Market, or SAM, for XPUs and network in the range of $60 billion to $90 billion in fiscal 2027 alone.
Tan further clarified to focus his views on AI connectivity & networks:
It's a very narrow Serviceable Addressable Market we're talking about. And we're talking about XPUs and AI connectivity at that scale, AI connectivity could probably – we estimate to run approximately close to 15% to 20% of the dollar content.
When analysts pressed Tan about how each of these 3 hyperscalers could deploy 1 million XPU clusters and the scope for scaling connectivity solutions given the massive size of deployment, he had this to say:
When you connect a cluster on a single fabric of 10,000 XPUs or GPU, a GPU and scale it up to 100,000 and on to 500,000 and 1 million is a whole new game in terms of architecture.
And so you guys hear the differences of when you do these racks, you have what you call scale up. And then you have joining rack to rack because you have no choice, you can’t get to 1 million or for that matter 100,000 otherwise, you call it scale out.
And that's a continuing, evolving architecture. But I think each of these hyperscale customers of ours have, at this point kind of figured out how to get there. Hence, a road map that will keep growing from 100,000 to 1 million XPU cluster. On pretty much, similar architecture basis over the next three years, four years.
What Tan was hinting at is that hyperscalers have figured out how to scale up the resources per server by packing in more GPUs/XPUs and other compute resources while also figuring out how to replicate the scale they achieved per server by scaling out to other server systems in the data center.
There were a couple of points we took away from this discussion in December.
First, the massive scale of deployment of XPUs creates robust opportunities for networking companies, including Broadcom, to position their products, such as switches, cables, routers, modems, wires, fiber, etc., in front of hyperscalers that are getting increasingly selective about spending their capex dollars because of the heightened scrutiny over capex budgets. This is one of the reasons why hyperscalers such as Alphabet’s Google GOOG 0.00%↑ and Amazon AMZN 0.00%↑ have already pivoted to custom designing their own AI chips.
Because these AI chips are white box chip products, it's also easy for hyperscalers to efficiently design their own networking architectures, which are independent of Nvidia’s expensive InfiniBand products.
Second, it's not like Nvidia’s InfiniBand was completely winning anyway. Nvidia’s recent earnings report showed that its Data Center Networking revenue growth was sliced in more than half, slowing to 52% growth in FY25 versus 133% growth in FY24. Nvidia’s networking revenue slowed much faster than its overall Data Center revenue, as seen below.

While InfiniBand gave Nvidia an initial boost at the height of all the GPU hoarding in 2023, it quickly faded as the company realized that hyperscalers were mostly unwilling to move away from Ethernet-based networking products.
Moreover, InfiniBand also needed a lot more bells and whistles, such as fiber optic transceivers and cables, adding to the overall expenses of deploying InfiniBand. So Nvidia launched their own Ethernet products last year while also joining the Ultra Ethernet Consortium.
At the time, in Nvidia’s Q1 FY25 earnings call, Nvidia’s CFO said:
Spectrum-X is ramping in volume with multiple customers, including a massive 100,000 GPU cluster. Spectrum-X opens a brand-new market to NVIDIA networking and enables Ethernet only data centers to accommodate large-scale AI. We expect Spectrum-X to jump to a multibillion-dollar product line within a year.
But as seen in Exhibit D above, Nvidia has not been really able to make that forceful an impact with its Spectrum-X Ethernet products.
That’s because networking also tends to be a very sticky business, and once a vendor has tied down a hyperscaler customer, the business tends to stick with the networking vendor.
Also, in general, there is usually a cyclical play shaping up, as seen in the chart below that compares Nvidia’s revenues versus the combined revenues of new-age pure-play networking companies such as Arista Networks ANET 0.00%↑ , Astera Labs ALAB 0.00%↑ , Celestica CLS 0.00%↑ , and Credo CRDO 0.00%↑ versus the combined revenues of custom silicon vendors such as Broadcom and Marvell MRVL 0.00%↑ .
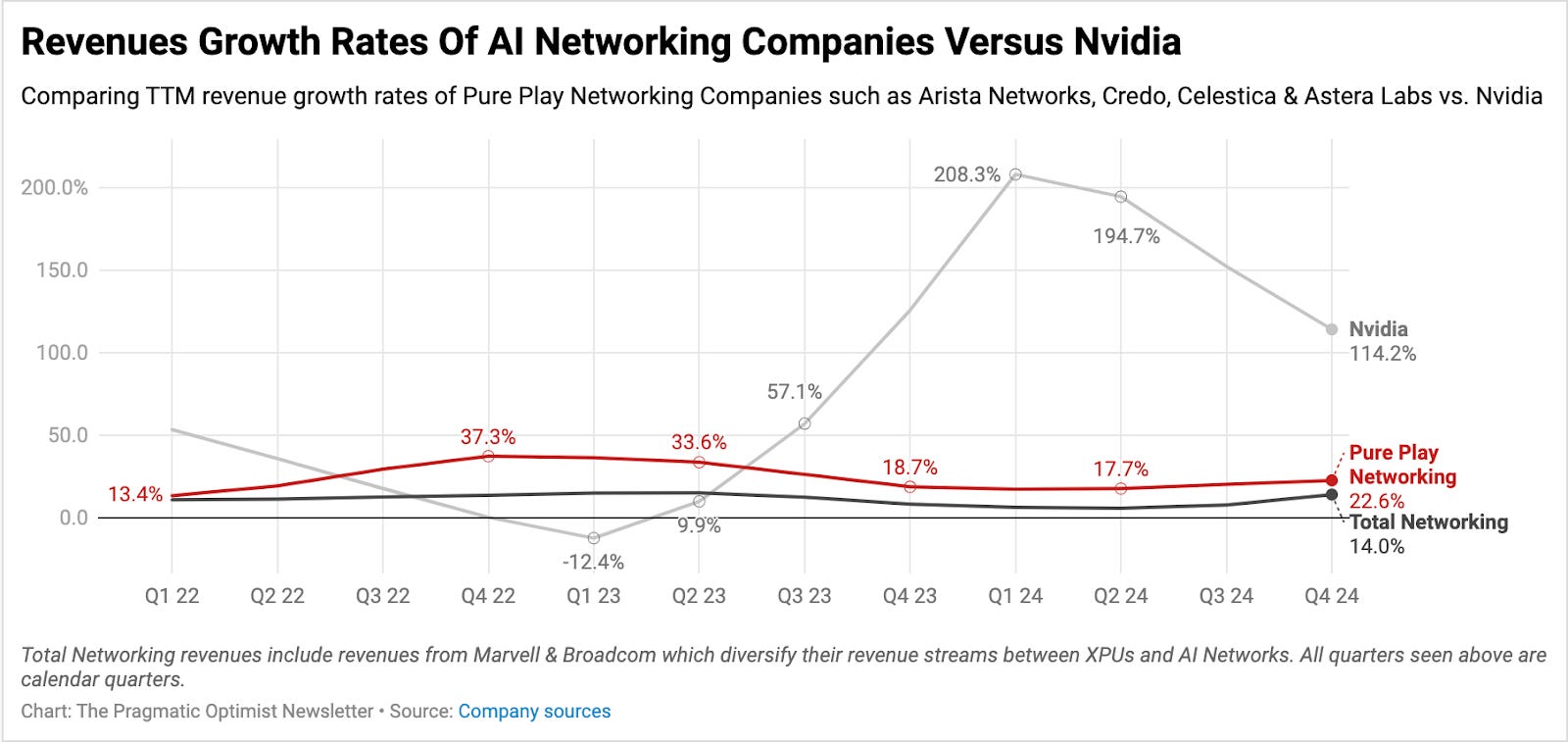
What this chart shows is that the revenue growth trajectory of new-age, pure-play networking companies and custom silicon companies that also have networking products has started accelerating towards the growth outlook that Broadcom’s Hock Tan laid out.
Even old guard, Cisco has seen a strong resurgence in its business in the past 2-3 quarters.
Networking Players & How They Compete Within The Networking Ecosystem
Within the vast umbrella of AI connectivity solutions, there are many products that are deployed in the network to achieve network efficiency at scale for cloud networks. What possibly increases the difficulty in keeping up with the networking space is all these products are spread across a host of networking standards as well.
If investors like to go deeper, we wholeheartedly recommend reviewing a recent paper by the generous engineering team at Meta Platforms, who illustrated how all the different networking products work together in their Grand Teton network topology below. We’ll also use this topology to highlight key products and key players.
A quick note about Meta’s Grand Teton platform. The Grand Teton platform is a modular GPU-based hardware platform designed to support large AI workloads with fully integrated power, control, compute, and fabric interfaces. Folks at Meta made the design modular so they could easily optimize the system for the company’s own needs. For example, they were able to expand the server design to support the inclusion of AMD’s MI300X GPU server system in October last year.
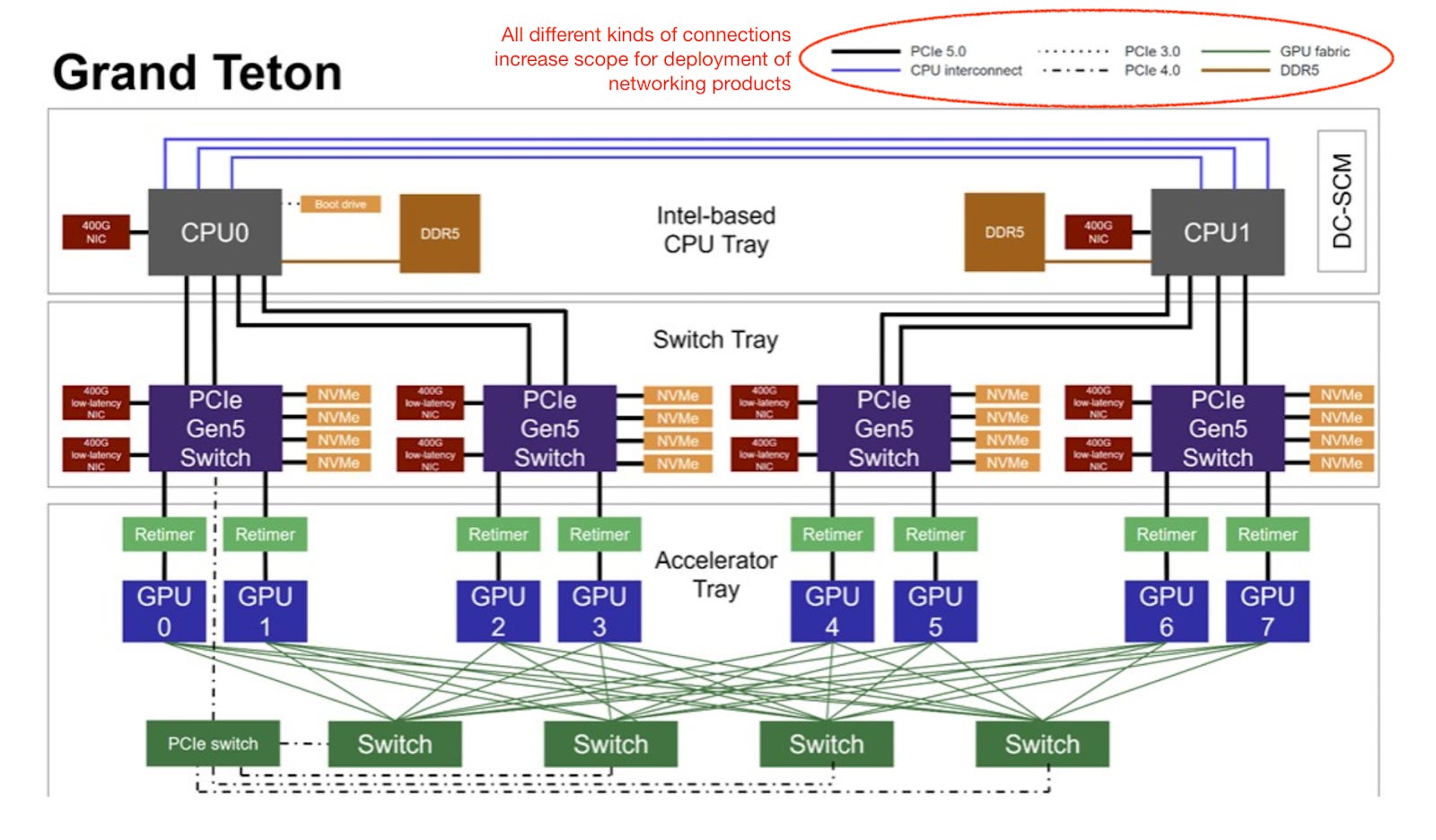
One look at the topology above, and one can already see networking products such as NICs or Network Interface Cards, switches, retimers, etc.
While Broadcom and Marvell also have their own switches, their custom silicon solutions, or ASICs (application-specific integrated circuits), are used by hyperscalers to custom design their own network switches.
For example, Meta’s team revealed that they custom-designed their own switch called Minipack3, which utilized Broadcom’s latest Tomahawk5 ASIC. Network switches are designed with specifications with Ethernet standards. Meta Platform’s Minipack3 switch is manufactured by Celestica.

Celestica has been one of the breakout stars in the Ethernet Data Center Switch market, and according to the Dell ’Oro Group, a networking-based market research firm, the company secured the largest market share gain last year. The research still holds Arista Networks as the market leader of the space ahead of Celestica and Nvidia.
Newer entrants in the wider networking market include Astera Labs, which introduced their industry-defining retimers, a tiny device that boosts the signals of GPUs. Astera Labs is also trying to push new industry-first memory controller products. Astera’s memory controller products are based on CXL, or Compute Express Link, networking standards.
Plus, Astera Labs is also positioning itself in Broadcom’s line of fire by beating the latter to deliver the industry’s first Scorpio Smart Fabric Switches. These switches are based on PCIe Gen 6 standards.
In addition to all the products, don’t forget wires as one of the key networking products that bind the entire network together. Hyperscalers employ different kinds of Ethernet, copper, and optical cables to make the connection. Credo Technologies, a company that mainly focuses on providing Active Electric Cables, or AECs, is gaining increasing access to hyperscalers capex.
Without diluting the importance of this high-level piece, the important point for investors here is constantly matching top-down, high-level overviews, such as today’s post, with the bottom-up performance of companies to understand which networking companies can deliver more alpha than the rest and at what cost to shareholder value.
Framing The Market Size For AI Networking Companies
At the end of last year, the 650 Group, another research firm, outlined how the entire custom silicon and AI connectivity market could easily average ~$100B a year in growth by 2028.
The 650 Group’s market assessment hinged on an assumption that about half of the technical component of AI Capex goes towards accelerators, while the remaining half goes towards data center networking:
If we look at our five-year forecasts, AI ASICs will rapidly approach $50B a year. The systems market for DC Switching will be north of $45B, Retimers is $1B+, AECs is $1B+, and the DSP business across intra-datacenter and DCI will drive $10B+ in transceivers revenue.
Adding that together, these announcements will touch over $100B/year market in systems revenue by 2028. This is significant and shows the magnitude of how larger the Hyperscalers and the overall data center market are getting.
Folks at the Dell ’Oro Group sort of agree in theory with research put out by the 650 Group but believe that not all networking standards will benefit equally. Analysts at the Dell ’Oro Group note:
Ethernet is experiencing significant momentum, propelled by supply and demand factors. More large-scale AI clusters are now adopting Ethernet as their primary networking fabric. One of the most striking examples is xAI’s Colossus, a massive NVIDIA GPU-based cluster that has opted for Ethernet deployment.
What’s also boosting the growth story for all Ethernet-standard network products is the Ethernet alliance has already introduced frameworks for 800G per second speeds, which most hyperscalers and enterprise firms are in the process of deploying already, while most of these companies will begin trialing 1.6TB per second solutions in H2 of this year. And most scale out networks are prime for getting built/upgraded with 800 Gbps to 1.6 Tbps Ethernet-based network systems.

But in general, the research paints a compelling growth narrative for many networking companies looking ahead, especially after considering how most of these stocks got KO-ed during the past few trading sessions.
What investors must watch out for is the earnings reports of the industry’s two largest peers, Marvell and Broadcom, whose earnings reports are being unwrapped as we write this, with Marvell’s full year FY25 earnings report being published yesterday and Broadcom’s earnings report on the cards today.
The reaction to Marvell’s earnings report as well as Credo’s Q3 FY25 earnings report highlights another comment Broadcom’s Tan made in the December call that investors should be mindful of seasonal volatility vs. secular stability.
We’ll end this post with Tan’s Terms & Conditions 🧐 that he added to his growth outlook last December, which is probably what is playing with Marvell this morning:
Keep in mind though, this will not be a linear ramp. We'll show quarterly variability.
That’s all for today. Stay tuned for our next research note in the coming week. Have a great week, y’all!!
Uttam & Amrita.
A very well-researched and in-depth article, excellent work! Thank you very much!
very nice overview